El proyecto persigue la identificación inequívoca de los sitios webs oficiales de las empresas con actividad económica en Euskadi.
Existen dos proyectos que surgieron con el objetivo de recopilar las URLs de las empresas incluidas en DIRAE, el directorio de actividades económicas de Eustat. Para ello, se emplean técnicas de scraping que aprovechan motores de búsqueda y datos clave de las empresas para obtener las URLs.
Ambos proyectos están programados en Python y Java. Se ejecutan de manera secuencial, asegurando que las empresas sin una URL identificada en el primer proyecto sean procesadas en el segundo.
Se desarrollan dos proyectos que van a ser complementarios para encontrar las URLs de las empresas. Los proyectos son los siguientes:
- Búsqueda de URLs utilizando el CIF de la empresa y la denominación
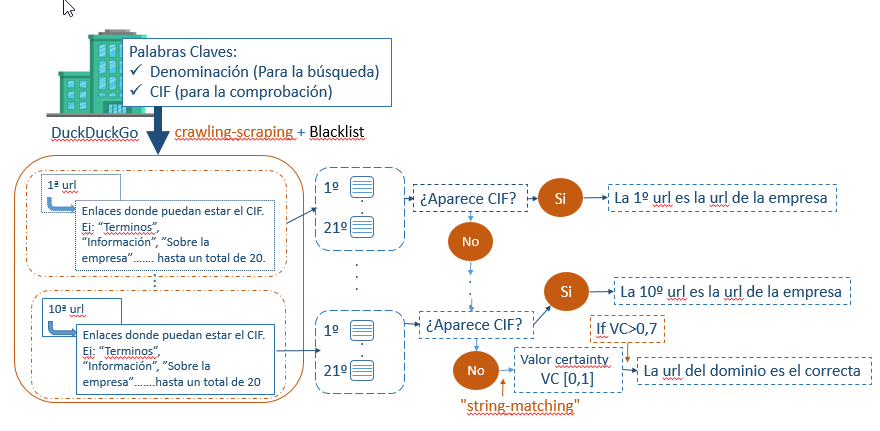
Partiendo del CIF y la denominación de la empresa. Se emplea el buscador DuckDuckGo para realizar un proceso de crawling y scraping de las primeras 10 URLs que aparecen en los resultados de búsqueda. Por cada uno de estos enlaces, se buscan coincidencias con el CIF de la empresa. Si se encuentra el CIF en alguno de estos enlaces, esa URL se considera la correcta. En caso contrario, se aplica un proceso de coincidencias (string-matching) entre la denominadión y el dominio de la URL, obteniendo un valor entre 0 y 1 que indica el nivel de similitud. Si el valor es mayor a 0.7, se considera que la URL es válida; si no, la empresa pasa al segundo proyecto para su procesamiento.
Desarrollo realizado a partir del Proyecto de los Institutos de Estadística de Austria y Finlandia en la ESSNet.
- Búsqueda de URLs utilizando el municipio y la denominación de la empresa
-
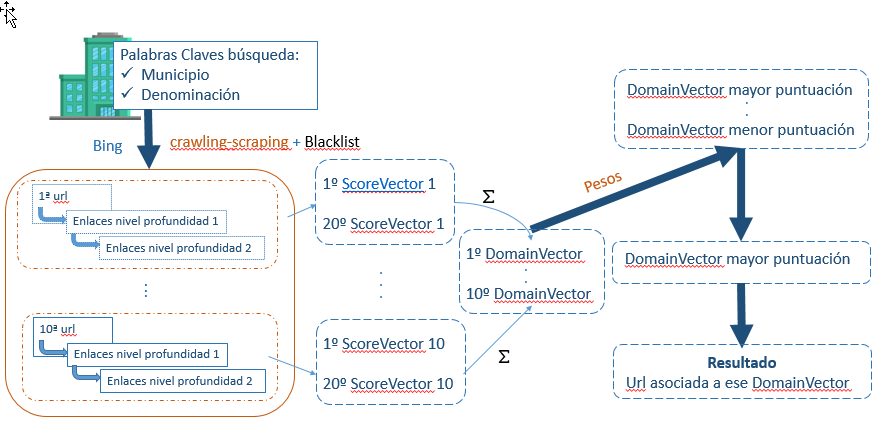
Este segundo proyecto se enfoca en las empresas para las que no se pudo obtener una URL válida en el primer proyecto. En este caso, se utiliza el buscador Bing para realizar un proceso de crawling y scraping, partiendo del municipio y la denominación de la empresa. Se extraen las 10 primeras URLs resultantes, descartando aquellas que figuran en una lista negra (como directorios o páginas no relevantes). El análisis se profundiza hasta el segundo nivel de enlaces de cada URL, generando un scoreVector para cada enlace, compuesto por 8 dígitos.
Cada uno de estos dígitos representa una variable clave:
• URL simple
• Teléfono
• Posición (esta variable utiliza dos dígitos)
• CIF
• Municipio
• Provincia
• Código postal
Estas variables clave se determinan a partir de la presencia de los datos reales de la empresa en el contenido extraído mediante el scraping. La "Posición" se refiere al lugar que ocupa la URL en los resultados del motor de búsqueda.
Tras calcular los scores, se realizan operaciones aritméticas y lógicas para cada dominio, obteniendo un domainVector. Este vector es ponderado y se utiliza para generar una valoración final. Para cada empresa, la URL con la valoración más alta es seleccionada como la candidata para ser la URL correcta.
Esta metodología asegura una mayor precisión en la obtención de URLs empresariales, aprovechando diferentes fuentes y enfoques de búsqueda.
Desarrollo realizado a partir del Proyecto del ISTAT (Instituto estadística de Italia) de la ESSNet y con la colaboración de la Universidad del País Vasco (Facultad de Informática).
Se trabaja con una muestra estratificada. Para la obtención de la muestra se consideran empresas con más de 10 empleados y se consideran 5 grupos para la estratificación. Se han realizado varias pruebas.
Se pueden destacar los siguientes resultados:
- Prueba realizada con empresas que ya de antemano conocemos la URL
Se ha tomado una muestra de 1.000 empresas, de las cuales se disponía de su URL, para llevar a cabo un proceso de scraping basado en la denominación y el municipio de cada empresa. Este proceso ha permitido extraer el contenido del 99,6 % de las empresas incluidas en la muestra.
Siguiendo el flujo del desarrollo de este procedimiento, hemos obtenido las URLs de las empresas. Para evaluar la efectividad de nuestro método, comparamos los resultados obtenidos con las URLs registradas en nuestro directorio de empresas (DIRAE). Como resultado de esta comparación, se ha obtenido un 70,5 % de acierto en la identificación correcta de las URLs.
- Prueba realizada con empresas que no tenemos la URL en nuestro directorio de empresas
En esta prueba, se trabaja con una muestra de 2.514 empresas sin web registrada en el directorio DIRAE. Durante el proceso de scraping, se obtuvo el contenido del 95,1 % de las empresas.
En la primera fase del proyecto, centrada en la búsqueda mediante el CIF de las empresas, se logró identificar URLs para el 16 % de las mismas. Las empresas que no obtuvieron resultados en esta fase fueron procesadas en la segunda fase, utilizando la búsqueda por denominación y municipio. Este enfoque permitió obtener URLs para un total del 53 % de las empresas que, inicialmente, no disponían de una página web en el directorio DIRAE.
Es importante señalar que algunas empresas podrían no contar con un sitio web, lo que podría influir en los resultados obtenidos.