The project aims to uniquely identify the official websites of companies with economic activity in the Basque Country.
There are two projects that emerged with the aim of compiling the URLs of companies included in Eustat’s Directory of Economic Activity (DIRAE). To do this, scraping techniques are used that utilise search engines and key company data to obtain the URLs.
Both projects are programmed in Python and Java. They run sequentially, ensuring that companies without an identified URL in the first project are processed in the second.
Two complementary projects are being developed to find the URLs of the companies. The projects are as follows:
- Search for URLs using the tax identification code [CIF] and name of the company
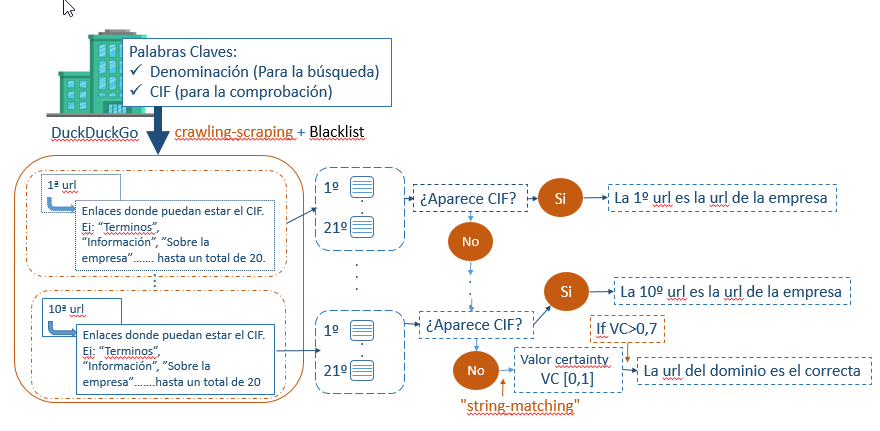
Starting with the tax identification code [CIF] and name of the company, the search engine DuckDuckGo is used to perform the process of crawling and scraping the first 10 URLs displayed in the search results. For each of these links, we look for matches with the company’s tax identification code [CIF]. If the tax identification code [CIF] is found in any of these links, that URL is deemed the correct one. Otherwise, a string-matching process is applied between the name and domain of the URL, giving a value between 0 and 1 that indicates the level of similarity. If the value is greater than 0.7, the URL is deemed valid; if not, the company proceeds to the second project for processing.
Development based on the ESSnet Project carried out by the Austrian and Finnish Statistics Institutes.
- Search for URLs using the municipality and name of the company
-
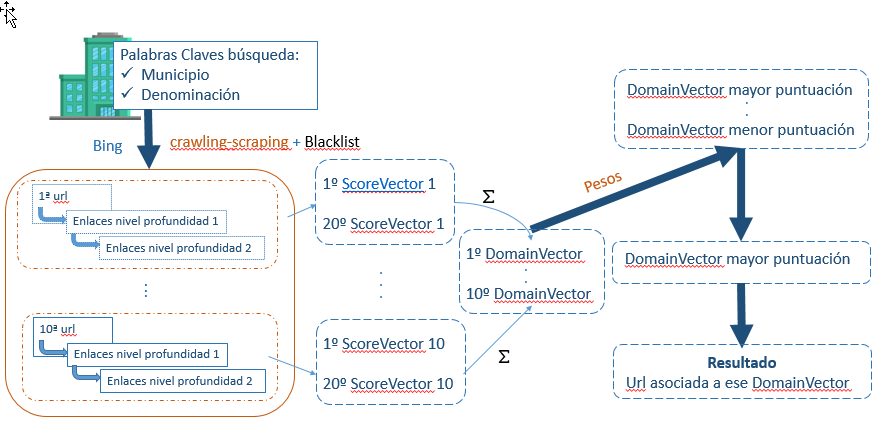
This second project focuses on the companies for which it was not possible to obtain a valid URL in the first project. In this case, the search engine Bing is used to perform a crawling and scraping process based on the municipality and name of the company. The first 10 resulting URLs are extracted, discarding those that are blacklisted (such as directories or non-relevant web pages). The analysis delves deeper into the second tier of links from each URL, generating a score vector for each link composed of 8 digits. Each of these digits represents a key variable:
• Simple URL
• Telephone
• Position (this variable uses two digits)
• Tax identification code [CIF]
• Municipality
• Province
• Postcode
These key variables are determined based on the presence of real company data in the content extracted via scraping. The “Position” refers to the URL's position in the search engine results.
After calculating the scores, arithmetic and logical operations are carried out for each domain to obtain a domain vector. This vector is weighted and used to generate a final score. For each company, the URL with the highest score is selected as the candidate for the correct URL.
This methodology ensures greater accuracy when obtaining company URLs by utilising different sources and search approaches.
Development based on the ESSnet Project carried out by ISTAT (Italian Institute of Statistics).
We work with a stratified sample.
In order to obtain the sample, companies with more than 10 employees are considered and 5 groups are considered for stratification.
Several tests have been carried out and it is worth highlighting the following results:
- Test carried out with companies whose URLs were already known to us
We took a sample of 1,000 companies whose URLs were available in order to carry out a scraping process based on the name and municipality of each company. This process made it possible to extract content from 99.6% of the companies included in the sample.
Following the flow of development of this procedure, we obtained the URLs of the companies. In order to evaluate the effectiveness of our method, we compared the results obtained with the URLs listed in our company directory (DIRAE [Directory of Economic Activity]). As a result of this comparison, we obtained a 70.5% success rate in correctly identifying the URLs.
- Test carried out with companies whose URLs were not in our company directory
In this test, we worked with a sample of 2,514 companies whose websites were not listed in the Directory of Economic Activity (DIRAE). During the scraping process, content was obtained from 95.1% of the companies.
In the first phase of the project, which focused on searching using the companies’ tax identification codes [CIFs], we were able to identify URLs for 16% of the companies. The companies that did not obtain results in this phase were processed in the second phase, using the search by name and municipality. This approach enabled us to obtain URLs for a total of 53% of the companies that did not initially have a website in the Directory of Economic Activity (DIRAE).
It is important to note that some companies may not have a website, which could influence the results obtained.